nvidia-smi topo matrix 살펴보기
nvidia-smi topo matrix 살펴보기
nvidia-smi의 기능에는 예전부터 포스팅에서 여러 번 말했지만 많은 정보들이 있다.
그중에 하나가 오늘 확인해볼 nvidia-smi topo -m이다.
우리가 GPU가 서로 통신할 때 또는 GPUDirect RDMA 등을 올바르게 사용하려면 GPU의 토폴리지를
잘 이해하고 어떻게 구성되어 있는지부터 정확히 알아야 할 것이다.
오늘 보여줄 GPU 서버는 nvlink type의 8 GPU v100 server이다.
[root@localhost v100]# nvidia-smi topo -m
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 CPU Affinity
GPU0 X NV1 NV1 NV2 NV2 SYS SYS SYS 0-13,28-41
GPU1 NV1 X NV2 NV1 SYS NV2 SYS SYS 0-13,28-41
GPU2 NV1 NV2 X NV2 SYS SYS NV1 SYS 0-13,28-41
GPU3 NV2 NV1 NV2 X SYS SYS SYS NV1 0-13,28-41
GPU4 NV2 SYS SYS SYS X NV1 NV1 NV2 14-27,42-55
GPU5 SYS NV2 SYS SYS NV1 X NV2 NV1 14-27,42-55
GPU6 SYS SYS NV1 SYS NV1 NV2 X NV2 14-27,42-55
GPU7 SYS SYS SYS NV1 NV2 NV1 NV2 X 14-27,42-55
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
TOPOLOGY:
topo Displays device/system topology. "nvidia-smi topo -h" for more information.
Options include:
[-m | --matrix]: Display the GPUDirect communication matrix for the system.
아래 설명처럼 x는 self를 의미하며, SYS는 결국 QPI/UPI CPU를 거친다는 의미이다.
마지막으로 NV#은 NV1과 NV2가 있으며 저건 어떤 차이가 있는지 사진으로 구조를 한번 확인해 보자.
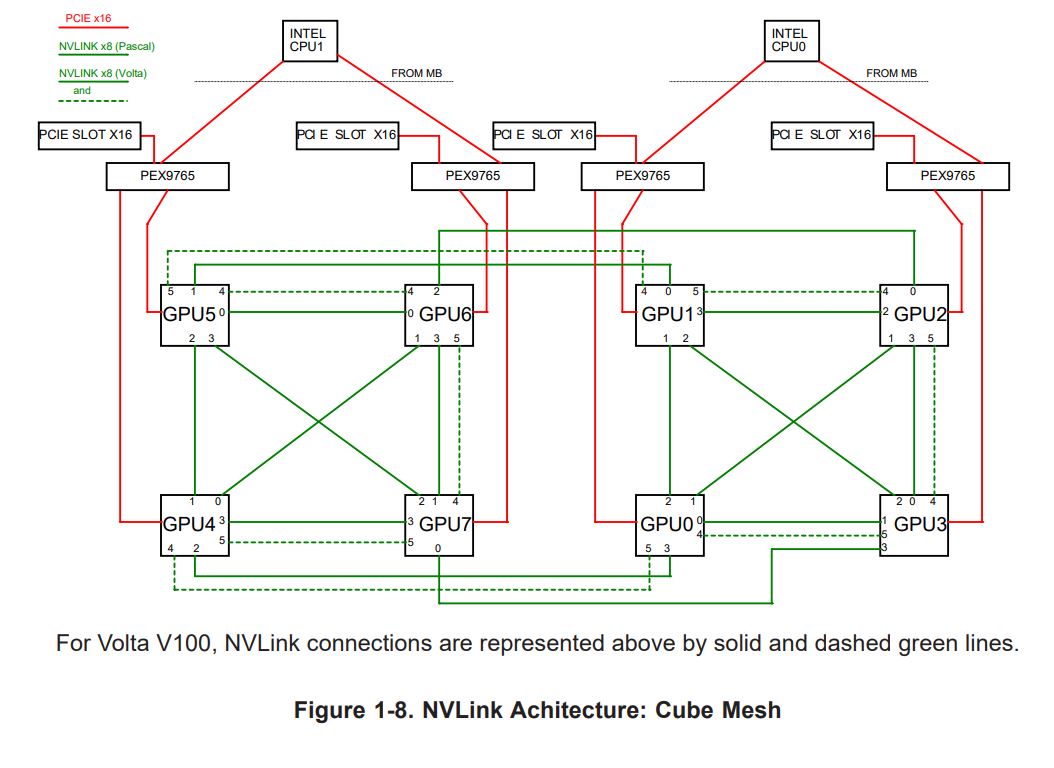
위에 nvlink 타입의 서버는 cube mesh의 형태로 되어있다.
아까 코드 블록에 적어 놓은 것처럼 NV1과 NV2차이는 NVLink가가 단방향으로 연결되어 있느냐, 혹은 양방향으로
연결되어 있느냐의 차이인 것이다.
2020/06/26 - [GPU] - GPU 용어 및 NVlink nvswitch
위 링크에 좀 더 자세히 설명했지만 Pascal은 nvlink 1.0이며 4개의 lane을 사용했지만
위의 v100 Volta는 nvlink 2.0을 사용하여 6개의 lane으로 구성되어 있다.
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 CPU Affinity
GPU0 X NV1 NV1 NV2 NV2 SYS SYS SYS 0-13,28-41
그렇기에 GPU0에서 GPU1, 2는 NV1이 되는 것이고
GPU0에서 GPU3, 4는 NV2
마지막으로 GPU5, 6, 7은 SYS가 된다, CPU의 QPI나 UPI를 탄다는 것이다.
지금 보여줄 샘플은 cuda 10.2 샘플이다.
cuda를 설치하게 되면 samples를 같이 설치할 수가 있다.
P2P Connectivity Matrix
D\D 0 1 2 3 4 5 6 7
0 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1
2 1 1 1 1 1 1 1 1
3 1 1 1 1 1 1 1 1
4 1 1 1 1 1 1 1 1
5 1 1 1 1 1 1 1 1
6 1 1 1 1 1 1 1 1
7 1 1 1 1 1 1 1 1
Unidirectional P2P=Disabled Bandwidth Matrix (GB/s)
D\D 0 1 2 3 4 5 6 7
0 731.51 9.84 11.03 11.03 11.05 11.06 11.06 11.06
1 9.92 739.82 11.05 11.02 11.06 11.08 11.05 11.08
2 11.08 11.08 739.82 9.87 11.05 11.05 11.05 11.04
3 11.10 11.09 9.91 737.03 11.04 11.07 11.07 11.07
4 11.10 11.09 11.09 11.11 737.03 9.91 11.07 11.07
5 11.10 11.08 11.08 11.12 9.95 735.64 11.06 11.05
6 11.10 11.08 11.08 11.11 11.11 11.12 738.42 9.91
7 11.08 11.07 11.09 11.08 11.11 11.12 9.99 737.03
Unidirectional P2P=Enabled Bandwidth (P2P Writes) Matrix (GB/s)
D\D 0 1 2 3 4 5 6 7
0 731.51 24.22 24.22 48.33 48.34 9.53 9.71 9.10
1 24.22 742.63 48.33 24.22 9.54 48.32 9.71 9.10
2 24.22 48.35 741.22 48.35 7.30 7.43 24.22 9.11
3 48.32 24.22 48.34 745.47 9.10 9.10 9.43 24.22
4 48.34 9.53 9.74 9.73 741.22 24.22 24.22 48.34
5 9.53 48.33 9.74 9.73 24.22 738.42 48.34 24.22
6 8.94 8.94 24.22 8.90 24.22 48.35 739.82 48.34
7 8.33 8.94 9.53 24.22 48.34 24.22 48.34 741.22
Bidirectional P2P=Disabled Bandwidth Matrix (GB/s)
D\D 0 1 2 3 4 5 6 7
0 744.76 10.37 19.07 18.92 18.80 18.94 18.99 17.35
1 10.45 745.47 18.92 18.94 18.87 18.92 18.87 17.41
2 18.95 18.96 745.47 10.45 18.99 18.94 18.97 17.46
3 18.96 18.84 10.49 749.76 18.92 18.93 18.96 17.39
4 18.90 18.96 18.90 18.96 746.18 10.48 18.94 17.50
5 18.95 19.01 19.07 18.87 10.51 745.47 19.06 17.46
6 19.00 18.90 18.92 19.04 18.91 19.03 745.47 10.48
7 17.53 17.48 17.62 17.43 17.49 17.46 10.47 745.47
Bidirectional P2P=Enabled Bandwidth Matrix (GB/s)
D\D 0 1 2 3 4 5 6 7
0 741.22 48.38 48.38 96.46 96.41 18.40 18.60 18.21
1 48.39 748.32 96.49 48.39 18.42 96.51 18.61 18.22
2 48.39 96.46 751.20 96.48 18.11 18.76 48.39 18.22
3 96.30 48.35 96.23 751.20 18.12 18.74 18.65 48.39
4 96.45 18.44 18.74 18.73 747.61 48.39 48.39 96.20
5 18.44 96.25 18.73 18.74 48.38 749.04 96.41 48.33
6 18.31 18.61 48.33 18.64 48.33 96.44 746.89 96.23
7 18.19 18.21 18.20 48.38 96.20 48.39 96.20 747.61
P2P=Disabled Latency Matrix (us)
GPU 0 1 2 3 4 5 6 7
0 1.66 17.61 17.13 17.42 16.77 16.60 16.60 16.71
1 17.30 1.68 17.11 17.10 18.47 18.47 18.63 18.63
2 17.38 17.13 1.66 17.33 18.48 18.47 18.46 18.46
3 16.78 16.77 16.72 1.64 17.89 17.90 17.80 17.92
4 17.51 17.44 17.57 17.48 1.66 16.48 16.47 16.46
5 17.63 17.54 17.60 17.68 16.45 1.61 16.85 16.44
6 18.49 18.43 18.43 18.70 16.53 16.48 1.70 16.49
7 16.44 16.46 16.45 16.43 16.06 16.21 15.95 1.63
CPU 0 1 2 3 4 5 6 7
0 3.84 11.85 11.57 11.65 11.51 9.61 9.48 9.68
1 11.22 4.51 12.27 12.25 11.70 10.52 10.39 10.47
2 11.52 12.25 4.46 12.15 11.72 10.38 10.33 10.36
3 10.99 12.26 12.15 4.50 11.66 10.41 10.25 10.30
4 10.62 11.90 11.83 11.92 4.26 10.02 9.95 9.88
5 9.68 10.98 10.89 10.80 10.43 3.55 9.14 9.11
6 9.79 10.99 10.84 10.91 10.41 9.16 3.46 9.38
7 9.86 11.16 11.07 10.97 10.52 9.21 9.16 3.57
P2P=Enabled Latency (P2P Writes) Matrix (us)
GPU 0 1 2 3 4 5 6 7
0 1.64 1.51 1.53 1.98 1.99 2.22 2.22 2.22
1 1.60 1.69 2.00 1.59 2.22 2.02 2.17 2.19
2 1.56 1.99 1.66 1.99 2.18 2.18 1.56 2.18
3 2.00 1.51 1.95 1.62 2.18 2.19 2.19 1.52
4 2.00 2.24 2.21 2.23 1.69 1.57 1.55 1.98
5 2.22 1.98 2.21 2.22 1.52 1.65 1.99 1.54
6 2.22 2.22 1.58 2.22 1.56 1.99 1.69 1.98
7 2.23 2.20 2.19 1.53 1.96 1.53 1.96 1.66
CPU 0 1 2 3 4 5 6 7
0 3.85 3.21 2.88 3.11 2.96 2.86 3.05 2.86
1 3.30 4.80 3.11 3.32 3.27 3.19 3.20 3.71
2 3.83 3.54 4.61 3.44 3.66 3.61 3.52 3.65
3 3.57 3.59 3.46 4.56 3.64 3.64 3.76 3.65
4 3.70 3.98 3.84 3.87 4.77 2.86 2.82 2.80
5 3.18 3.25 3.33 3.30 3.24 4.55 3.23 3.24
6 3.15 3.13 3.20 3.29 3.23 3.25 4.57 3.18
7 3.08 3.06 3.08 3.26 3.18 3.24 3.13 4.47
위 코드블럭에 나와있는 수치와 nvidia topology를 비교해 보면서 확인하면 될 것 이다.
'GPU' 카테고리의 다른 글
| Nvidia RTX 30 시리즈 정보 (3090, 3080, 3070) (1) | 2020.09.02 |
|---|---|
| ubuntu18.04 desktop nvidia driver troubleshooting (6) | 2020.08.21 |
| NVIDIA GPU 적정 온도는 어떻게 될까?? (0) | 2020.08.19 |
| Nvidia gpu 장치 확인하는 방법 (4) | 2020.08.18 |
| Tensorflow python packages list (2) | 2020.08.15 |